火车采集器Python插件Http请求插件异常
- 作者:zhanhy ——来源:原创 ——火车采集器支持插件处理一些采集器本身无法处理的问题,比如只采集某网站当天的文章而文章链接地址当中有时间串,这样我们在列表页采集详情页时,就可以只要当天的文章链接。如果链接地址当中不含有时间串,又想要只采集当天的文章,我们会在另外的文章进行讲解。在今天实现这个步骤的过程中发现火车采集器Python插件Http请求插件异常,但是内容处理插件可以正常使用。下面就说下发现这个问题的过程。
测试网址:http://www.moe.gov.cn/jyb_xwfb/ 由于只想采集当天的文章,采集器本身无法满足这个需求,因此智能进行插件处理。开始写完插件之后测试提示python插件语法错误,一直提示语法错误。最后我把个人修改的代码部分删除掉还提示语法错误。无奈之下开始咨询客服,客服说了几点问题后,仍然提示语法错误。最后证实,在现有的版本中火车采集器Python插件,Http请求插件异常,存在BUG。预计会在下个版本或者下下个版本才能解决。估计那个时候我的升级时间也到期了,不过还是记录下要注意的几个问题。
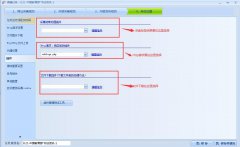
1、Http请求插件在使用时要在对应的区域选择使用如下图所示
采集结果处理插件——可以修改内容采集后的各个标签
Http请求、响应修改插件——可以修改发送HTTP请求和请求结果的插件
文件下载插件——可以修改下载文件之前所需要的请求参数等

2、确定该种插件确定这种模式可用
站长就是没确认,结果浪费了半天时间,希望可以引以为戒,避免浪费时间。
下面给出例子网站只采集当天文章的php插件,具体插件实现的原理可以自行领悟,如果有问题的话可以在文章下面留言。
<?php
error_reporting(E_ERROR | E_WARNING | E_PARSE);
switch($LabelArray['PageType'])
{
case 'List'://处理列表页,只能处理html
$formatted_today=date('Ymd', time());
$pattern='#(<[^>]*?href="(?:http://www.moe.gov.cn/jyb_xwfb|.)/[\w/]+/\d+/t'.$formatted_today.'_\d+.html"[^>]*?>)#';
preg_match_all($pattern,$LabelArray['Html'],$pat_array);
$LabelArray['Html']=implode($pat_array[0]);
break;
}
echo serialize($LabelArray);
?>如果你还有其它疑问可以来本站搜索相关问题,这里会有你想要的答案:火车脚本网
你会喜欢下面的文章?


还有什么疑问可以提出来
- 全部评论(0)

还没有评论,快来抢沙发吧!